

专栏作者1:@大咕咕咕驴。工作范畴:出海用户增长、营销、i18n。TikTok早期团队成员。因为看到AIGC在外贸电商领域的能量,希望从非技术的视角记录和分享新技术在行业里落地应用、改造和被改造的过程。 专栏作者2:@殷迦南,资深全栈,GitChat/极客学院的积极分享者;主导团队用技术手段驱动国内一线珠宝品牌数十亿年利润增长。希望和大家分享我的技术探索之旅。 本专栏希望探讨:AI大热窗口期,如何抓住机会实现相关技术的快速落地,以技术变现或提效?
使用Snack Prompt免费查看创意prompt
不知道你们有没有听说过Promptbase, 就是一个可以在线买卖prompt的工具。很多人在上面卖prompt,但我今天想推荐是另外一款类似的工具,可以免费查看其他人的prompt。它的功能类......
AutoGPT:通过AI加速OpenAI API调用
好像大家最近都在关注AutoGPT,一个可以通过使用GPT模型和Pinecone DB来实现目标,当然也能构建任务列表的工具。然后就有些人出来修改了这些工具,创造了一个叫chaos GPT的工具......
ChatGPT封号?傻瓜式替代方案(1)
最近我发现市面上有很多浏览器插件,接下来打算为大家推荐几款好用的插件。第一款是Wiseone,能够帮助你更好地掌握阅读内容的AI阅读助手。它不仅可以提取文章摘要,还能自动标注人名地名等特殊词汇。......
Mermaid X ChatGPT:轻松生成流程图!
让ChatGPT生成代码并通过第三方工具绘制流程图已经不是问题了!除了上一期列举的几种格式之外,我们还可以让ChatGPT为您生成更多不同类型的图表,比如状态图、ER图和甘特图等等。 (http......
让ChatGPT生成特定格式的答案
长段落文本,采用适当的缩进和间距进行组织,以提高可读性。
示例:Can you explain the his......
ChatGPT具体应用场景及自用Prompt
要求他们围绕*主题*集思广益,列出一个想法清单,在列表中挑选一个项目,深入了解
已有具体问题和想法,但过于大众化,缺少新奇的角度
Top......
如何基于ChatGPT接口部署一个机器人
在前文中,我们部署了一个基于OpenAI接口的机器人,该接口基于GPT-3模型。但是,官方ChatGPT网站上提供的接口与该接口有很大的差异。因此,本文将梳理ChatGPT官网上的......
如何快速部署一个OpenAI机器人
本文介绍了如何使用 OpenAI 官方提供的 API 部署 ChatGPT,并以企业微信机器人为例,快速实现自然语言理解和生成功能。
本文还对官方文档提供的模型和 ChatGPT 使用的模型进行了比较,并提供了使用 golang、python、PHP 和 nodejs 等常见语言请求 ChatGPT 的代码。本文会大致说一下基于企业微信、飞书、钉钉等工具自建的机器人的相关流程,其中企业微信机器人的代码可以参考项目:https://github.com/thlz998/openai-bot
快速部署
先看看如何使用`docker一行代码运行OpenAI机器人(企业微信版本)
``` bash
docker run -d -p 3201:3200 \
-e api_key="[chatgpt的APIkey]" \
-e app_port=":3200" \
-e app_model="text-davinci-003" \
-e wework_token="[企业微信自建应用的API token]" \
-e wework_encodingAeskey="[企业微信自建应用的encodingAeskey]" \
-e wework_corpid="[企业微信企业唯一ID]" \
-e wework_secret="[企业微信自建应用的secret]" \
-e wework_agentid="[企业微信自建应用的agentid]" \
ibfpig/openai-wework:1.0.0
# 记得把用中括号OpenAI的相关信息和企业微信的相关信息换成自己的,其中OpenAI的apikey可以直接访问这个链接来创建和获取:https://platform.openai.com/account/api-keys
如果觉得部署机器人麻烦,我们来看看最重要的是什么:
curl -X "POST" "https://api.openai.com/v1/completions" \
-H 'Authorization: Bearer [这里换成你的API key]' \
-H 'Content-Type: application/json; charset=utf-8' \
-d $'{
"prompt": "你好",
"frequency_penalty": 0,
"model": "text-davinci-003",
"temperature": 0.7,
"presence_penalty": 0,
"max_tokens": 2000,
"top_p": 1
}'
# 记得把这一行代码中的api key换成自己的api key,可以直接访问这个链接来创建和获取:https://platform.openai.com/account/api-keys
机器人流程原理
我们部署的机器人大概得流程是这样的:
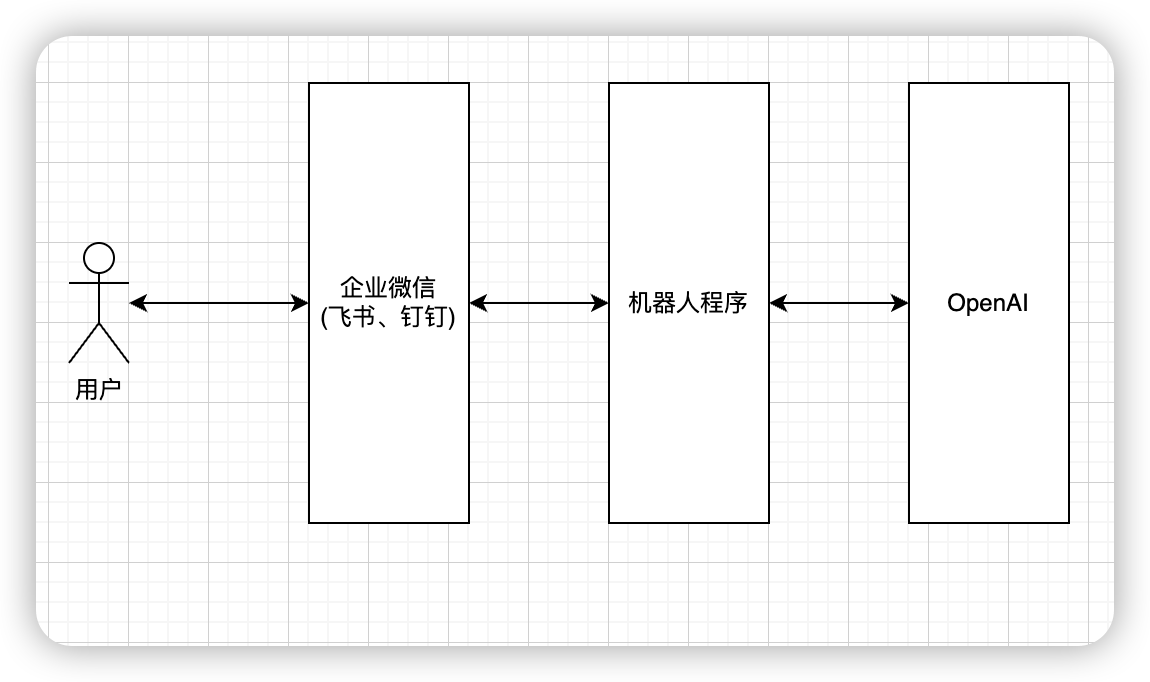
用户直接与企业微信自建应用聊天,之后企业微信会将收到的消息回调给我们写的机器人程序,我们拿到用户请求的内容去发给ChatGPT,等ChatGPT回复我们之后,我们再通过企业微信把消息发送给用户。
很好理解,其实就是以下三个步骤
1. 接收企业微信的应用消息
2. 发送请求给ChatGPT并拿到返回的内容
3. 通过企业微信给用户回复消息
如何自建企业微信应用
(钉钉飞书流程差不多,可以具体参考相关文档)
新建企业微信应用
登录企业微信后台,在应用管理中,点击创建应用,设置好你的机器人的logo、名字,并选择可以使用机器人的企业微信用户
查看Secret并记录下来
设置企业可信IP,这个可信ip就是指能够给企业微信发送请求的服务器ip,需要是对外的公网ip,如果有服务器就填服务器的公网ip,如果在本地运行,就看看https://ip138.com 上写的地址是啥就填啥就可以了
在接收消息这一栏点那一行设置API接受消息,URL填这个https://xxxx.com/api/wework,其中,Token和EncodingAESKey点随机获取就可以了,这个时候点保存肯定会提示不通过,我们先停在这个页面,然后开始编码。如果是在本地电脑上做调试,需要做好反向代理,目标是能通过一个域名访问到本地的一个服务
使用docker部署企业微信机器人
(代码在文章开头已经提供了,具体如下)
docker run -d -p 3201:3200 \
--name openai-wework \
-e api_key="[chatgpt的APIkey]" \
-e app_port=":3200" \
-e app_model="text-davinci-003" \
-e wework_token="[企业微信自建应用的API token]" \
-e wework_encodingAeskey="[企业微信自建应用的encodingAeskey]" \
-e wework_corpid="[企业微信企业唯一ID]" \
-e wework_secret="[企业微信自建应用的secret]" \
-e wework_agentid="[企业微信自建应用的agentid]" \
ibfpig/openai-wework:1.0.0
3. 查看日志,确定服务运行是否正常
docker logs -f openai-wework
4. 去企业微信测试即可
关于请求OpenAI的参数
这里会简单做个说明,后边在详细聊如何训练OpenAI的时候会做更详细的说明
prompt: "需要给OpenAI理解文字",
frequency_penalty: 0, #一个介于-2.0和2.0之间的数字。当它是正数时,会对新的token进行惩罚,根据它们在文本中已经出现的频率,减少模型重复相同文本的可能性。这个参数可以控制模型生成文本的创新性和多样性。
model: "text-davinci-003", # 模型ID,目前API里效果最好的就是text-davinci-003,但是也是最慢的
temperature: 0.7, # 0~1之间,随机性,越高,随机性越高
presence_penalty: 0, # -2.0~2.0之间,是一个用于控制模型输出是否跟之前已经输出的文本相关的参数。如果这个参数的值为正数,那么模型会更倾向于生成与之前不同的单词,从而使生成的文本更加丰富多样,涉及到更多的话题。
max_tokens: 2000, # 生成文本时所允许的最大单词数量
top_p: 1 # 这种方法会限制生成的文本只包含最可能的一些词,而不会像用温度进行抽样一样随机生成词语。同时,通常建议只更改temperature或top_p中的一个参数,而不是同时更改两个参数。
node、PHP、Python、golang请求OpenAI的代码示例
javascript(使用axios)
axios({
"method": "POST",
"url": "https://api.openai.com/v1/completions",
"headers": {
"Authorization": "Bearer [你自己的API key]",
"Content-Type": "application/json; charset=utf-8"
},
"data": {
"prompt": "你好",
"frequency_penalty": 0,
"model": "text-davinci-003",
"temperature": 0.7,
"presence_penalty": 0,
"max_tokens": 2000,
"top_p": 1
}
})
php
// Include Guzzle. If using Composer:
// require 'vendor/autoload.php';
use GuzzleHttp\Pool;
use GuzzleHttp\Client;
use GuzzleHttp\Psr7\Request;
$client = new Client();
$request = new Request(
"POST",
"https://api.openai.com/v1/completions",
[
"Authorization" => "Bearer [你自己的API key]",
"Content-Type" => "application/json; charset=utf-8"
],
"{\"model\":\"text-davinci-003\",\"prompt\":\"\\u4f60\\u597d\",\"max_tokens\":2000,\"temperature\":0.7,\"top_p\":1,\"frequency_penalty\":0,\"presence_penalty\":0}");
$response = $client->send($request);
echo "Response HTTP : " . $response->getStatusCode() . "
";
python
# Install the Python Requests library:
# `pip install requests`
import requests
import json
def send_request():
# 对话
# POST https://api.openai.com/v1/completions
try:
response = requests.post(
url="https://api.openai.com/v1/completions",
headers={
"Authorization": "Bearer [你自己的API key]",
"Content-Type": "application/json; charset=utf-8"
},
data=json.dumps({
"prompt": "你好",
"frequency_penalty": 0,
"model": "text-davinci-003",
"temperature": 0.7,
"presence_penalty": 0,
"max_tokens": 2000,
"top_p": 1
})
)
print('Response HTTP Status Code: {status_code}'.format(
status_code=response.status_code))
print('Response HTTP Response Body: {content}'.format(
content=response.content))
except requests.exceptions.RequestException:
print('HTTP Request failed')
golang
package main
import (
"fmt"
"io"
"net/http"
"bytes"
)
func send() {
// 对话 (POST https://api.openai.com/v1/completions)
json := []byte(`{"prompt": "你好","frequency_penalty": 0,"model": "text-davinci-003","temperature": 0.7,"presence_penalty": 0,"max_tokens": 2000,"top_p": 1}`)
body := bytes.NewBuffer(json)
// Create client
client := &http.Client{}
// Create request
req, err := http.NewRequest("POST", "https://api.openai.com/v1/completions", body)
// Headers
req.Header.Add("Authorization", "Bearer [你自己的API key]")
req.Header.Add("Content-Type", "application/json; charset=utf-8")
// Fetch Request
resp, err := client.Do(req)
if err != nil {
fmt.Println("Failure : ", err)
}
// Read Response Body
respBody, _ := io.ReadAll(resp.Body)
// Display Results
fmt.Println("response Status : ", resp.Status)
fmt.Println("response Headers : ", resp.Header)
fmt.Println("response Body : ", string(respBody))
}
殷迦南:OpenAI实际应用怎么快速落地
大家好,我是殷迦南。资深全栈工程师,有着丰富的技术分享经验。
作为团队的小核心,我参与和主导过多项技术项目,为国内一线珠宝品牌带来了数十亿的年度利润。现在也在尽快推进 AIGC 的落地应用,帮助国内一线消费品牌赋能提效。
在这个专栏中,我将和大家分享我的技术探索之旅,带来最前沿、最实用的技术知识。
未来,我分享的内容将涵盖以下几个方面:
I. 如何部署OpenAI AI机器人
1. chat.openai.com
2. 使用OpenAI官方API
II. 解决官网版本机器人的问题
1. 处理plus权限的问题
2. 解决cloudflare机器人验证问题
3. 利用多账号实现负载平衡
III. 训练OpenAI AI模型
1. 阅读官方文档,了解模型和demo
2. 微调OpenAI官方模型的实例
2. 尝试生成图像
2. 练习代码补全
IV. OpenAI AI在实际场景的应用
1. 利用AI学习英语:听说读写(或者其他?)
#抓住机会,利用AIGC技术变现或提效
如果 AIGC 是下一次工业革命的话,这个专栏关注和试图记录的就是:
手把手教你学用珍妮纺纱机
注意注意:用翼锭来纺粗......